Remote Direct Memory Access (RDMA) is a high-performance networking technology that allows direct message passing from application virtual memory on one system to application virtual memory on another system. This message passing not only avoids the intermediate buffer copies that are required by TCP, but also bypasses the operating system kernel, resulting in higher throughput, lower latency, and lower CPU utilization than can be obtained on traditional networks. The three popular transport implementations of RDMA are InfiniBand, iWARP (Internet Wide-Area RDMA Protocol), and RoCE (RDMA over Converged Ethernet). The software layer is provided by the OpenFabrics Software (OFS) verbs library, which provides direct access to the RDMA hardware from userspace. The verbs library is powerful but also daunting to the network programmer, due to the complexity of direct access to the hardware.
For just over a year, I have been working on UNH EXS development. UNH EXS is based on the Extended Sockets API produced by the Open Group. This API provides two extensions to the traditional sockets API to support RDMA using OpenFabrics Software (OFS) in a way that is familiar to network programmers.
The first extension is memory registration, which allows virtual memory buffers to be directly accessed by the RDMA hardware. The second extension is event queues, which allow asynchronous socket I/O operations.
These two extensions to normal sockets define a sockets-like interface that will be familiar to most programmers, but does not hide the RDMA features needed to achieve high performance.
In aiming to require no changes to Linux or OpenFabrics Software, UNH EXS supplies some additional extensions to run entirely in userspace, preventing it from being a drop-in replacement for normal sockets. The library is designed to be used by user threads in Linux, and is implemented entirely by the use of userspace OFS verbs. Both SOCK_STREAM and SOCK_SEQPACKET sockets are supported. Sockets in SOCK_SEQPACKET mode take advantage of the message orientation of the underlying RDMA transports, whereas SOCK_STREAM sockets implement TCP stream-like semantics on RDMA.
Below are the results from a simple performance study that we did using a blast-type program, which rapidly sends messages in one direction. Each run used a certain number of messages of a given size. In this way, we could have several outstanding operations at a time, due to the asynchronous nature of EXS. Figure 1 shows the throughput over an FDR link connecting two systems back-to-back. The results show that the highest performance (about 48 Gbps) can be reached at a message size of 2 mebibytes with either two or four simultaneously outstanding messages. Figure 2 shows that the CPU usage goes down significantly (to nearly 0% of elapsed time) as the message size increases, regardless of the number of simultaneously outstanding messages. This is unlike TCP performance, because RDMA eliminates the intermediate buffer copies that are done in TCP.
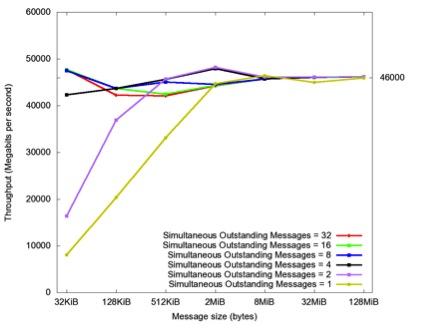
Figure 1. Throughput vs. message size for UNH EXS message blast over FDR InfiniBand.
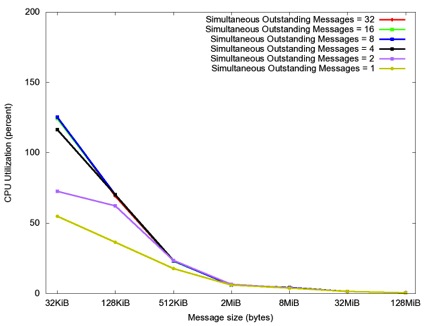
Figure 2. CPU usage vs. message size for UNH EXS blast over FDR InfiniBand. CPU usage is out of 200% because UNH EXS uses an internal thread to poll for RDMA completions.
Figures 3 and 4 show performance results with a ping-pong program, which sends a single message back and forth between two systems. Here we are measuring the average round-trip time. We compare two different mechanisms in EXS for delivering RDMA completion notifications. The first is notification, where the EXS completion thread gives up the CPU until the arrival of RDMA completion event(s), at which point the thread wakes up and processes the event(s). The second technique is busy polling, where the EXS completion thread continually polls the underlying RDMA completion queue for events. Busy polling uses 100% of a CPU but will process an event as soon as it arrives (as opposed to event notification, which must wait for the kernel's interrupt handlers to complete before processing the event). We also compare the effect of pinning the completion thread to a single CPU core. According to Figure 3, the lowest-latency configuration is to use busy polling and CPU pinning together, which reduces the latency by 1/3, from about 30 microseconds to about 10 microseconds. However, this must be balanced against the CPU cycles wasted by busy polling.
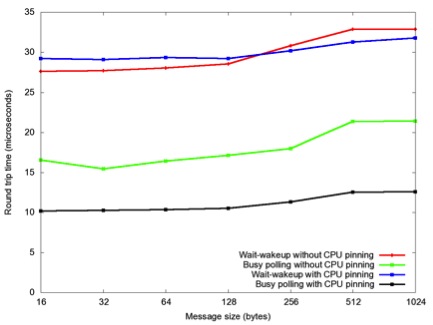
Figure 3. Round-trip time vs. message size for UNH EXS ping over FDR InfiniBand.
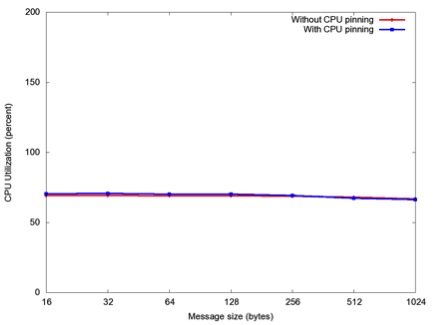
Figure 4. CPU usage vs. message size for UNH EXS ping over FDR InfiniBand. The busy polling cases (not shown) use 100% CPU. CPU usage is out of 200% because UNH EXS uses an internal thread to poll for RDMA completions.
We can see that UNH EXS can achieve very high throughput on an FDR InfiniBand link. Also, through a combination of busy polling and careful CPU pinning, the round-trip time can be reduced to mere microseconds. However, to get this performance the programmer must be willing to write the network I/O in an asynchronous manner, such that multiple socket I/O operations are simultaneously outstanding. We hope to improve the performance of UNH EXS further and reduce the burden on the programmer, but scaling up to exascale will require some changes to traditional computer networking paradigms.
The UNH EXS Version 1.3.0 distribution can be downloaded via the UNH-IOL website from our UNH-EXS Distribution Page.
Acknowledgements/Disclaimer
This material is based upon work supported by the National Science Foundation under award number OCI-1127228. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Patrick MacArthur, Research and Development